코드는 다 만든 지... 3주가 넘어가는데, 다른 일로 좀 바빠서 이제야 글을 쓰네요...
이번 시간에는 이 프로젝트의 핵심인 영화 정보를 가져오는 코드와 그 방법을 설명하겠습니다.
# 가져올 내용

저는 붉은 상자의 내용을 가져올 계획입니다. 이때 줄거리와 평점은 다른 탭에 있는 걸 확인할 수 있습니다. 그래서 눌러보면 티가 안 나지만 저 url 부분에 파란 상자가 보이시죠?? basuc, point로 바뀌는 걸 알 수 있습니다. 그 부분만 유의해서 정보를 가져오면 됩니다.
아! 추가로 포스터도 가져올 겁니다.
그래서 가져올 정보는 아래와 같습니다.
-> 제목, 장르, 국가, 상영시간, 개봉 연도, 감독, 출연배우(일부), 등급, 줄거리, 네티즌 평점, 네티즌 평점 평가 인원, 포스터 이미지, 영화 고유 코드
한 영화당 총 12개의 정보를 가져옵니다. 다만, 영화마다 일부 내용이 없을 수는 있습니다.
기본적으로
https://movie.naver.com/movie/bi/mi/basic.naver?code=
의 html은 가져왔다고 가정하고 코드를 설명하겠습니다.
1. 영화 제목

영화 제목은 저 붉은 상자에서 가져오는 게 아니라, 탭 이름을 통해서 가져옵니다.
이유는,,, 해보니까 영화 제목이 없는 경우가 더러 있더라...입니다. 이유는 모르겠지만.
그래서 저 탭으로 영화 제목을 가져오면 그런 경우가 없어서 탭에서 영화 제목을 가져왔습니다.
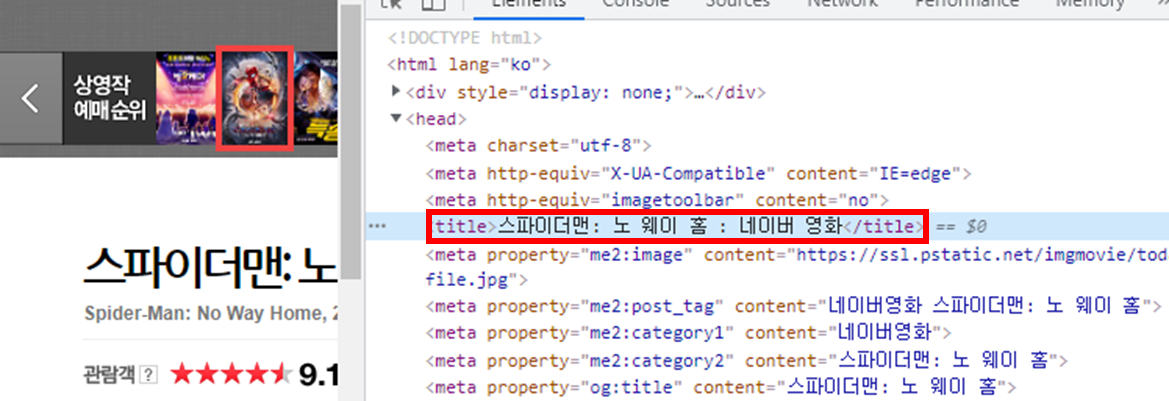
코드는 다음과 같습니다.
|
1
|
title = soup.find('head').find('title').text.replace(' : 네이버 영화','')
|
cs |
간단하죠? head에 title의 text를 가져오고, 뒤에 ' : 네이버 영화'를 지우면 끝입니다.
2. 장르, 국가, 상영시간, 개봉 연도, 감독, 출연, 등급 - 7개

이 부분은 "태그는 dl, 클래스는 info_spec"인 영역을 먼저 가져오면 됩니다.
|
1
|
info_spec = soup.find('dl','info_spec')
|
cs |
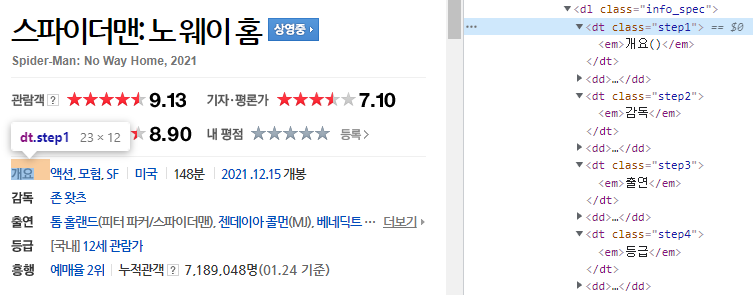
info_spec을 펼쳐보면 dt, dd 태그가 나열돼있습니다. 이때
dt는 개요, 감독, 출연, 등급
dd는 각 내용(?)이 됩니다.
'개요'같은 경우는 여러 정보가 함께 있습니다. 그래서 각 정보가 존재하는지를 잘 파악해서 가져와야 합니다.
어떻게 할 거냐면 url로 파악하면 됩니다.
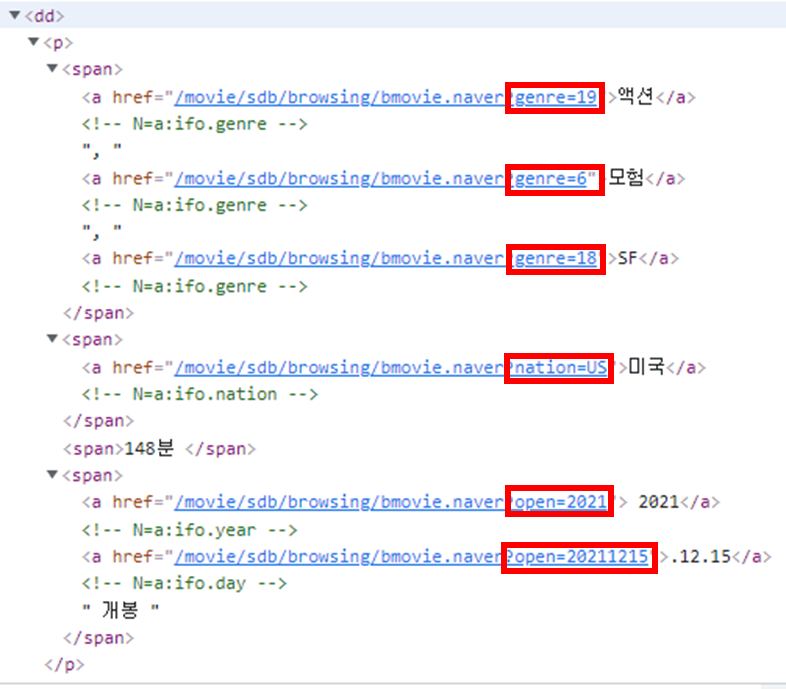
상영시간을 제외하면 장르는 url에 genre라 쓰여있고, 국가는 nation 등등 확인이 가능합니다.
나머지, 감독/출연/등급은 <dt>에 해당 문구가 적혀있는지 여부로 가져오면 됩니다.
전체 코드는 다음과 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
def getInfoSpec(html):
dtList = html.find_all('dt')
ddList = html.find_all('dd')
# 딕셔너리로 가져올 정보를 미리 정해 놓는다.
info = {'장르':'',
'상영시간':'',
'국가':'',
'개봉':'',
'감독':'',
'출연':'',
'등급':''}
# dt, dd의 개수만큽
for dt, dd in zip(dtList, ddList):
if '개요' in dt.text:
for span in dd.find_all('span'):
if '분' in span.text:
info['상영시간'] = span.text
else:
for a in span.find_all('a'):
if 'genre' in str(a):
# 공연실황 제외 - 이건 뭐 하는건지?
# 멜로/로맨스 - 이상한 19금 영화가 엄청 많음, 어떻게 거를 방법이...
if '공연실황' in a.text:
continue
if info['장르'] != '':
info['장르'] += ', ' + a.text
else:
info['장르'] = a.text
# 국가도 여러개인 경우가 있네요
elif 'nation' in str(a):
if info['국가'] != '':
info['국가'] += ', ' + a.text
else:
info['국가'] = a.text
# 재개봉 영화의 경우 개봉이 여러개로 들어온다.
elif 'open' in str(a):
if info['개봉'] != '':
info['개봉'] += a.text
else:
info['개봉'] = a.text
elif '감독' in dt.text:
for a in dd.find_all('a'):
# 감독이 여러명인 경우가 있어서 - 루소 형제 등?
if info['감독'] != '':
info['감독'] += ', ' + a.text
else:
info['감독'] = a.text
elif '출연' in dt.text:
for a in dd.find_all('a'):
# 메인 출연진이 아니라면 pass
if '더보기' in a.text:
continue
if info['출연'] != '':
info['출연'] += ', ' + a.text
else:
info['출연'] = a.text
# 등급의 경우 한국 등급만 가져오려면 수정이 필요
# 한국 등급이 없는 경우를 대비해서 일본, 미국 등의 등급이라도 가져오기 위해
# 별다른 수정은 안 했습니다.
elif '등급' in dt.text:
for a in dd.find_all('a'):
if 'grade' in str(a):
if info['등급'] != '':
info['등급'] += ', ' + a.text
else:
info['등급'] = a.text
return info
|
cs |
3. 줄거리
생각보다 줄거리가 까다롭네요?
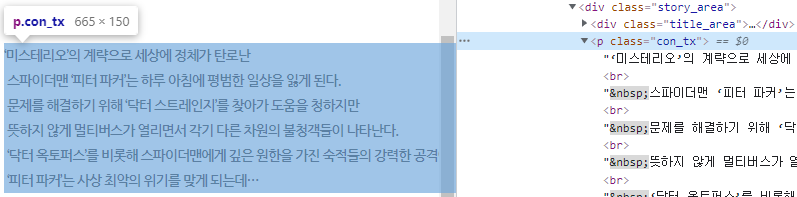
<p> 태그에 con_tx 클래스를 가져오면 됩니다.
가져오는 건 별 문제가 아닌데, 알 수 없는 엔터 등의 문제가 있습니다.
<br>이 html에서 enter 역할인데, 그 밑에 가 있는 걸 확인할 수 있습니다.
아마, 제가 알기론 저건 공백인데 저 부분 때문에 조금 오래 걸렸습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def getStory(url):
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
story = soup.find('p','con_tx')
if story is not None:
story = str(story).replace('<p class="con_tx">','').replace('</p>','').replace('\n','').replace('\t','')
# <br/>뒤에 있는 공백은 ' '이 아니라 '\xa0'이다.
# 공백이 html에서 로 표현되서 그렇나 봄?
story = story.replace('<','<').replace('>','>').replace('\r','').replace('\xa0','')
return story
return False
else :
print(response.status_code)
|
cs |
코드는 다음과 같습니다.
가 곧 \xa0 같네요
4. 네티즌 평점, 평가 인원 - 2개
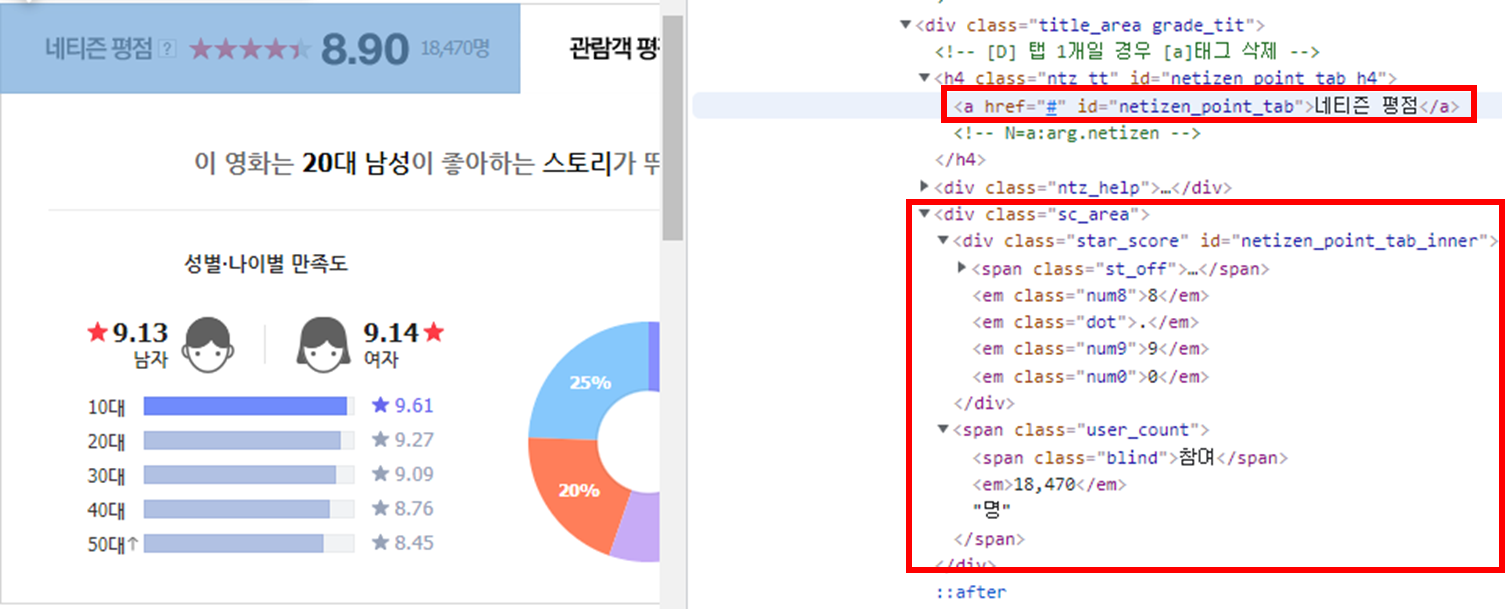
이거는 뭐 '네티즌 평점'이라는 text가 있으면 그 아래 내용을 가져오면 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def getRate(htmls):
rate = ''
participate = ''
for html in htmls:
if html.find('a', id='netizen_point_tab') is None:
continue
if html.find('a', id='netizen_point_tab').text == '네티즌 평점':
for val in html.find('div', 'star_score').find_all('em'):
rate += val.text
if rate != '':
participate = html.find('span', 'user_count').find('em').text
return rate, participate
return False, False
|
cs |
간단하죠??
5. 포스터 이미지
포스터 이미지가 생각보다 크더라고요.
그래서 포스터 이미지는 쓰레드로 동작시켜서 내용을 가져오는 것과 분리를 했습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def getImage(path, codes):
if not os.path.isdir(os.path.join(path)):
os.makedirs(path)
for code in codes:
url = f'https://movie.naver.com/movie/bi/mi/photoViewPopup.naver?movieCode={code}'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
imgUrl = soup.find('img', id='targetImage')
if imgUrl is not None:
imgUrl = imgUrl.attrs['src']
with open(os.path.join(path, code+'.png'), 'wb') as poster:
poster.write(requests.get(imgUrl).content)
else:
print(response.status_code)
|
cs |
코드는 다음과 같습니다. 이 코드에 뭐 따로 쓰레드가 있는 건 아니고, 전체 동작에서 쓰레드로 진행했습니다.
이미지 다운은 request 라이브러리를 썼습니다.
## 전체 코드 ##
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
|
from bs4 import BeautifulSoup
import requests
import os
import threading
from multiprocessing import Process
savePath = r'C:\Users\home\Desktop\as'
def getMovieCodeByYear(year):
movieCode = []
url = f'https://movie.naver.com/movie/sdb/browsing/bmovie.naver?open={year}&page=10000'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
# html에서 div 태그 중 class이름이 pagenavigation 태그를 찾아라
pagenavigation = soup.find('div','pagenavigation')
# pagenavigation내 <a> 태그 중 마지막 태그의 text 값
lastPage = pagenavigation.find_all('a')[-1].text
for i in range(1, int(lastPage)+1):
url = f'https://movie.naver.com/movie/sdb/browsing/bmovie.naver?open={year}&page={i}'
response2 = requests.get(url)
if response2.status_code == 200:
html = response2.text
soup = BeautifulSoup(html, 'lxml')
# html에서 ul 태그 중 class이름이 directory_list 태그를 찾아라
directory_list = soup.find('ul','directory_list')
allA = directory_list.findAll('a')
for a in allA:
if '?code=' in str(a):
movieCode.append(str(a).split('?code=')[1].split('"')[0])
else :
print(response2.status_code)
else :
print(response.status_code)
return year, movieCode
def getMovieInfo(year_codes):
global savePath
year = year_codes[0]
codes = year_codes[1]
delim = '\t' # 각 요소 별 구분자, 콤마(,)는 제목,장르 등에 쓰이기 때문에 탭(\t)으로 구분.
f = open(os.path.join(savePath, f'{year}.csv'), 'w', encoding='UTF-8')
f.write('openYear'+delim)
f.write('code'+delim)
f.write('title'+delim)
f.write('genre'+delim)
f.write('nation'+delim)
f.write('runningTime'+delim)
f.write('age'+delim)
f.write('openDate'+delim)
f.write('rate'+delim)
f.write('participate'+delim)
f.write('directors'+delim)
f.write('actors'+delim)
f.write('story'+delim+'\n')
t = threading.Thread(target=getImage, args=(os.path.join(savePath, str(year)), codes))
t.start()
for i, code in enumerate(codes):
#print(f'{i}/{len(codes)}', end='\r')
url = f'https://movie.naver.com/movie/bi/mi/point.naver?code={code}'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
title = soup.find('head').find('title').text.replace(' : 네이버 영화','')
rate, participate = getRate(soup.find_all('div','title_area grade_tit'))
info_spec = soup.find('dl','info_spec')
f.write(str(year)+delim) # year
f.write(code+delim) # code
f.write(title+delim) # title
if info_spec is not None:
info_spec = getInfoSpec(info_spec)
f.write(info_spec['장르']+delim) # genre
f.write(info_spec['국가']+delim) # nation
f.write(info_spec['상영시간']+delim) #runningTime
f.write(info_spec['등급']+delim) # age
f.write(info_spec['개봉']+delim) #openDate
# 네티즌 평점
if rate:
f.write(rate+delim+participate+delim)
else:
f.write(delim+delim)
f.write(info_spec['감독']+delim) # directors
f.write(info_spec['출연']+delim) # actors
story = getStory(f'https://movie.naver.com/movie/bi/mi/basic.naver?code={code}')
if story:
f.write(story)
f.write('\n')
else :
print(response.status_code)
f.close()
def getRate(htmls):
rate = ''
participate = ''
for html in htmls:
if html.find('a', id='netizen_point_tab') is None:
continue
if html.find('a', id='netizen_point_tab').text == '네티즌 평점':
for val in html.find('div', 'star_score').find_all('em'):
rate += val.text
if rate != '':
participate = html.find('span', 'user_count').find('em').text
return rate, participate
return False, False
def getStory(url):
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
story = soup.find('p','con_tx')
if story is not None:
story = str(story).replace('<p class="con_tx">','').replace('</p>','').replace('\n','').replace('\t','')
# <br/>뒤에 있는 공백은 ' '이 아니라 '\xa0'이다.
# 공백이 html에서 로 표현되서 그렇나 봄?
story = story.replace('<','<').replace('>','>').replace('\r','').replace('\xa0','')
return story
return False
else :
print(response.status_code)
def getImage(path, codes):
if not os.path.isdir(os.path.join(path)):
os.makedirs(path)
for code in codes:
url = f'https://movie.naver.com/movie/bi/mi/photoViewPopup.naver?movieCode={code}'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
imgUrl = soup.find('img', id='targetImage')
if imgUrl is not None:
imgUrl = imgUrl.attrs['src']
with open(os.path.join(path, code+'.png'), 'wb') as poster:
poster.write(requests.get(imgUrl).content)
else:
print(response.status_code)
def getInfoSpec(html):
dtList = html.find_all('dt')
ddList = html.find_all('dd')
# 딕셔너리로 가져올 정보를 미리 정해 놓는다.
info = {'장르':'',
'상영시간':'',
'국가':'',
'개봉':'',
'감독':'',
'출연':'',
'등급':''}
# dt, dd의 개수만큽
for dt, dd in zip(dtList, ddList):
if '개요' in dt.text:
for span in dd.find_all('span'):
if '분' in span.text:
info['상영시간'] = span.text
else:
for a in span.find_all('a'):
if 'genre' in str(a):
# 공연실황 제외 - 이건 뭐 하는건지?
# 멜로/로맨스 - 이상한 19금 영화가 엄청 많음, 어떻게 거를 방법이...
if '공연실황' in a.text:
continue
if info['장르'] != '':
info['장르'] += ', ' + a.text
else:
info['장르'] = a.text
# 국가도 여러개인 경우가 있네요
elif 'nation' in str(a):
if info['국가'] != '':
info['국가'] += ', ' + a.text
else:
info['국가'] = a.text
# 재개봉 영화의 경우 개봉이 여러개로 들어온다.
elif 'open' in str(a):
if info['개봉'] != '':
info['개봉'] += a.text
else:
info['개봉'] = a.text
elif '감독' in dt.text:
for a in dd.find_all('a'):
# 감독이 여러명인 경우가 있어서 - 루소 형제 등?
if info['감독'] != '':
info['감독'] += ', ' + a.text
else:
info['감독'] = a.text
elif '출연' in dt.text:
for a in dd.find_all('a'):
# 메인 출연진이 아니라면 pass
if '더보기' in a.text:
continue
if info['출연'] != '':
info['출연'] += ', ' + a.text
else:
info['출연'] = a.text
# 등급의 경우 한국 등급만 가져오려면 수정이 필요
# 한국 등급이 없는 경우를 대비해서 일본, 미국 등의 등급이라도 가져오기 위해
# 별다른 수정은 안 했습니다.
elif '등급' in dt.text:
for a in dd.find_all('a'):
if 'grade' in str(a):
if info['등급'] != '':
info['등급'] += ', ' + a.text
else:
info['등급'] = a.text
return info
def crawling(s, e):
for i in range(s, e+1):
getMovieInfo(getMovieCodeByYear(i))
if __name__ == "__main__":
p1 = Process(target=crawling, args=(2000, 2012))
p2 = Process(target=crawling, args=(2013, 2022))
p1.start()
p2.start()
p1.join()
p2.join()
|
cs |
파일은 csv로 저장되며, 구분자는 탭(\t)입니다.

결과는 다음과 같습니다.
이것으로 "네이버에서 영화 정보를 가져오는 크롤러" 포스팅은 마치겠습니다.
감사합니다 ^^
'토이프로젝트 > [크롤링] 네이버 영화 크롤링하기' 카테고리의 다른 글
| [크롤링] 네이버에서 영화정보 가져오기 - #5 ('국가 -> 개봉연도' 변경) (0) | 2022.01.05 |
|---|---|
| [크롤링] 네이버에서 영화정보 가져오기 - #4 (방향잡기) (0) | 2022.01.02 |
| [크롤링] 네이버에서 영화정보 가져오기 - #3 (HTML 알아보기) (0) | 2022.01.01 |
| [크롤링] 네이버에서 영화정보 가져오기 - #2 (Beautifulsoup 사용해 보기) (0) | 2022.01.01 |
| [크롤링] 네이버에서 영화정보 가져오기 - #1 (환경셋팅) (0) | 2022.01.01 |




댓글