크롤링을 하려면 기초적인 HTML을 알아야 합니다. 그래야 어느 부분을 가져올지, 링크를 어떻게 넘어갈지 등에 대한 방향을 잡을 수 있기 때문입니다. 그래서 지금부터 브라우저를 이용해 기초적인 html을 알아보고자 합니다.

열심히 만들진 않았지만,,, ㅎㅎ 보면 일반적으로 html은 다음과 같은 구조를 갖습니다. 전체 틀인 html에 head와 body가 있습니다. 그리고 body안에 내용을 div, ul, li, a, span, section, nav, table 등등 각종 상황에 따른 태그가 오게 됩니다.
사이트에 html을 보면 수만은 태그들 사이에 특정 태그에 대한 속성을 주고 싶을 때가 있습니다. 여기선 그 태그로 div를 사용하겠습니다. 2개의 div가 있는데 이 들 중에 가장 먼저 나오는 첫 번째 div를 찾고 싶으면 어떻게 할까요? 간단합니다. 이름을 붙여주면 됩니다. 이름은 2가지 방식으로 붙일 수 있습니다. class를 쓰거나 id를 쓰는 거죠. class와 id의 차이는 지금은 중요하지 않습니다. 그냥 저 녹색 div를 찾기 위해서 "class이름은 one을 id이름은 first를 줬다"라고 생각하면 되는 거죠. 두 번째 노란색 div도 마찬가지입니다. 다만 노란색 div는 class이름이 두 갭니다. 코드를 보면 tow, tree (심지어 스펠링을 둘 다 틀렸네요; 죄송합니다...)라고 쓰여있습니다. 그럼 class이름이 tow thee라고 생각할 수 있겠지만! 아닙니다. 띄어쓰기(스페이스, 공백)는 다른 이름을 쓰겠다는 소립니다. 이 개념은 참 중요해요. 웬만한 사이트에 class, id에 다수개의 이름이 붙기 때문입니다. 아무튼 그래서 노란색 div는 총 3개의 이름을 갖는 거지요. 이 정도를 알았다면 앞으로 영화 사이트를 통해 어떻게 html에서 정보를 찾는지에 대해 알아보겠습니다!
1. 브라우저에서 '검사' 속성 사용해보기

우리는 저 '검사기'와 'inspector'만 있다면, 두려울 것 없이 html을 휘 저울 수 있습니다.
영화를 보면 다양한 정보가 있습니다.
-> 장르, 상영시간, 개봉일, 감독, 출연, 등급, 평점 등등 앞으로 이런 속성을 어떻게 가져올지 알아보고자 합니다.
2. inspector 사용해보기

인스펙터를 누르고 원하는 정보에 마우스를 가져가면 (3)에서 해당 텍스트를 확인할 수 있습니다.
(3)에서 우클릭을 하면 창(? 내비게이션?)이 뜹니다. 여기서 '복사'의 무적의 'XPath'만 있다면 못 가져올 텍스트는 없지만, 아쉽게도 저희는 저 XPath를 많이 사용할 일은 없습니다. 왜냐하면! 장르가 1개인 영화도 있지만 2, 3, 4 등 여러 개인 영화도 있습니다. 때문에 동적으로 값을 가져와야 하는 상황에서는 XPath를 사용하는 건 어렵다고 생각됩니다.
3. HTML의 TREE구조

html은 tree구조를 이룹니다. 이미지를 보면 <dl> tag 아래 <dt>, <dd>가 있는 걸 확인할 수 있습니다.
그럼 앞으로 파이썬에서 bs4를 사용해 html을 가져올 때 html 내 수많은 dl 중 class 이름이 'info_spec'인 dl태그와 그 하위 html만 가져오면 [장르, 상영시간, 감독, 출연, 등급]의 정보를 얻을 수 있는 거죠.
이때 사실 저 <dl class="info_spec">을 찾기 위해서 XPath를 사용할 수 있습니다. 혹인 bs4의 다양한 함수들 [find, findall, class 등]을 활용할 수도 있습니다. 저 같은 경우는 네이버에서 영화 정보를 가져올 때 XPath를 사용하지 않을 것 같습니다. 왜냐하면 하나의 페이지에서 정보를 가져오는 게 아니라 수십만 페이지를 훑으면서 파싱을 하는 것이기 때문에 혹시 옛날 영화나 알 수 없는 특정 상황 때문에 혹은 네이버 개발자의 코드 수정으로 XPath가 바뀐다면 분명 정보가 있음에도 대응할 수 없기 때문이죠. 물론 class, id 이름이 바뀐다면 상황이 같겠지만, 적어도 XPath보단 안전하단 생각이 듭니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=136900'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'lxml')
# html에서 dl 태그 중 class이름이 info_spec인 태그를 찾아라
info_spec = soup.find('dl','info_spec')
print(info_spec)
else :
print(response.status_code)
|
cs |
코드는 다음과 같습니다.
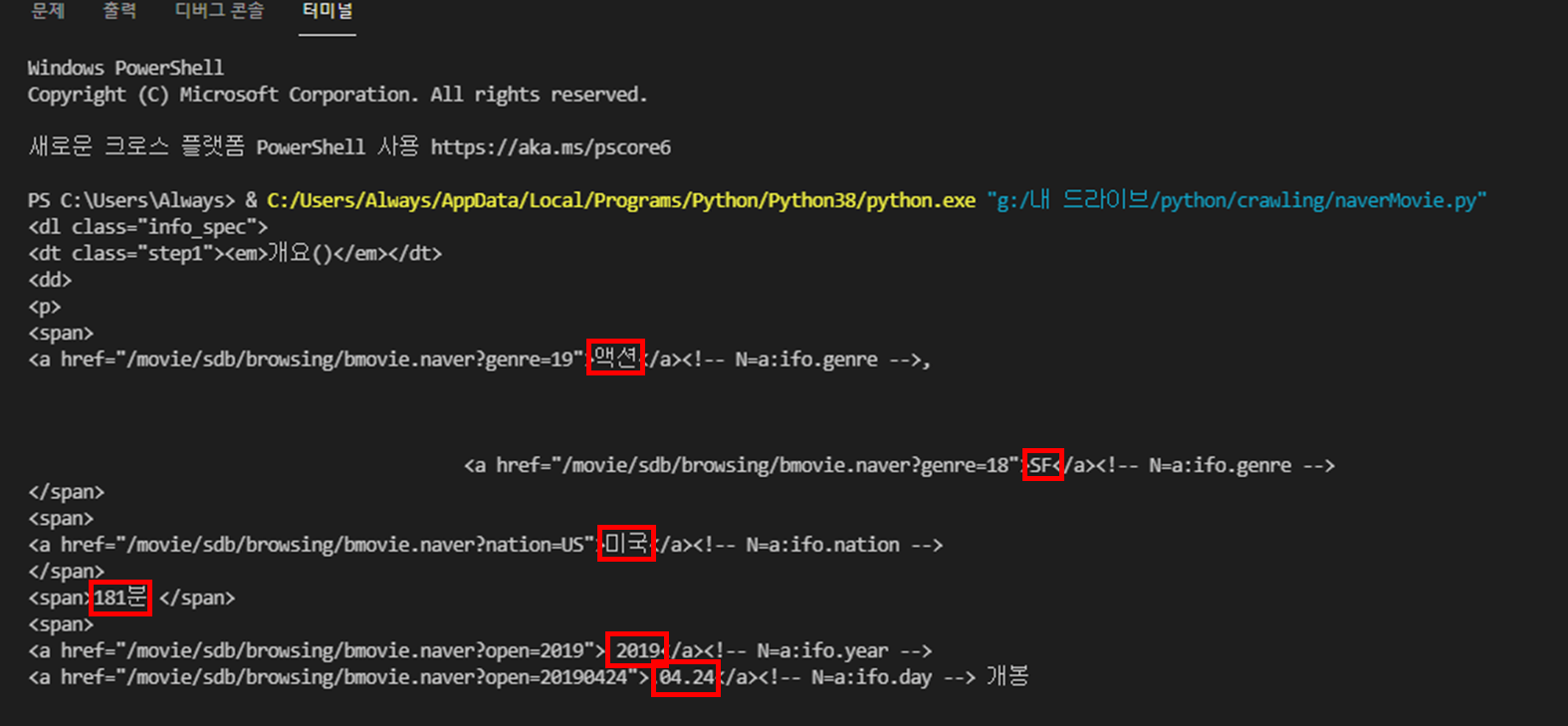
그럼 이렇게 다양한 정보를 얻어올 수 있습니다.
'토이프로젝트 > [크롤링] 네이버 영화 크롤링하기' 카테고리의 다른 글
| [크롤링] 네이버에서 영화정보 가져오기 - #6 영화정보 가져오기 (끝) (0) | 2022.01.26 |
|---|---|
| [크롤링] 네이버에서 영화정보 가져오기 - #5 ('국가 -> 개봉연도' 변경) (0) | 2022.01.05 |
| [크롤링] 네이버에서 영화정보 가져오기 - #4 (방향잡기) (0) | 2022.01.02 |
| [크롤링] 네이버에서 영화정보 가져오기 - #2 (Beautifulsoup 사용해 보기) (0) | 2022.01.01 |
| [크롤링] 네이버에서 영화정보 가져오기 - #1 (환경셋팅) (0) | 2022.01.01 |




댓글